CentOS 7 に Hadoop シングルノード クラスター (擬似ノード) をインストールする方法
Hadoop は、ビッグデータを処理するために広く使用されているオープンソース フレームワークです。ほとんどのビッグデータ/ データ分析プロジェクトはHadoop エコシステム上に構築されています。 2 つの層で構成されており、1 つはデータの保存用、もう 1 つはデータの処理用です。
ストレージはHDFS (Hadoop 分散ファイルシステム) と呼ばれる独自のファイルシステムによって処理され、処理が行われます。 YARN (Yet Another Resource Negotiator) が担当します。 Mapreduce はHadoop エコシステムのデフォルトの処理エンジンです。
この記事では、Hadoop の擬似ノードをインストールするプロセスについて説明します。ここには、すべてのデーモン (JVM) がインストールされます。 CentOS 7 上で単一ノードクラスタを実行しています。
これは主に Hadoop を学ぶ初心者向けです。リアルタイムでは、Hadoop がマルチノード クラスターとしてインストールされ、データがサーバー間でブロックとして分散され、ジョブが並列で実行されます。
前提条件
- CentOS 7 サーバーの最小限のインストール。
- Java v1.8 リリース。
- Hadoop 2.x 安定版リリース。
このページでは
- CentOS 7 に Java をインストールする方法
- CentOS 7 でのパスワードレス ログインのセットアップ
- CentOS 7 に Hadoop シングルノードをインストールする方法
- CentOS 7 で Hadoop を構成する方法
- NameNode を使用した HDFS ファイル システムのフォーマット
CentOS 7 への Java のインストール
1. Hadoop はJava で構成されるエコシステムです。 Hadoop をインストールするには、Java をシステムに強制的にインストールする必要があります。
yum install java-1.8.0-openjdk
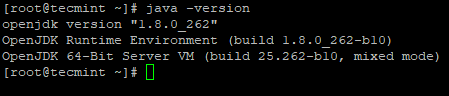
2. 次に、システムにインストールされている Java のバージョンを確認します。
java -version
CentOS 7 でのパスワードレス ログインの構成
マシンに SSH を設定する必要があります。Hadoop はSSH を使用してノードを管理します。マスターノードはSSH接続を使用してスレーブノードに接続し、起動や停止などの操作を実行します。
マスターがパスワードなしで ssh を使用してスレーブと通信できるように、パスワードなしの ssh を設定する必要があります。それ以外の場合は、接続を確立するたびにパスワードを入力する必要があります。
この単一ノードでは、マスター サービス (ネームノード、セカンダリ ネームノード、リソース マネージャー) とスレーブ< サービス (Datanode と Nodemanager) は、別個の JVM として実行されます。単一ノードであっても、 認証なしでマスターがスレーブと通信できるようにするには、パスワードなしの ssh が必要です。
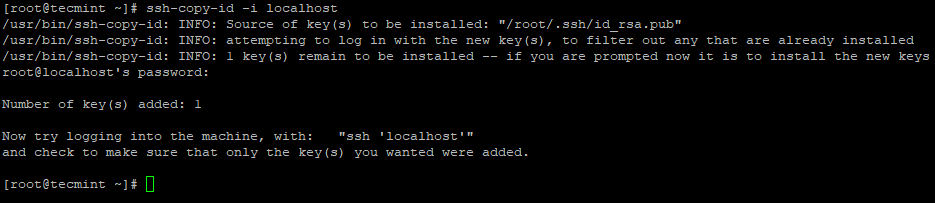
3. サーバー上で次のコマンドを使用して、パスワードなしの SSH ログインを設定します。
ssh-keygen
ssh-copy-id -i localhost

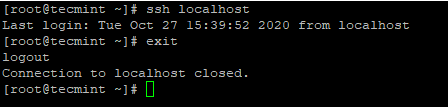
4. パスワードなしの SSH ログインを設定した後、再度ログインしてみると、パスワードなしで接続されます。
ssh localhost
CentOS 7 への Hadoop のインストール
5. Apache Hadoop Web サイトに移動し、次の wget コマンドを使用して Hadoop の安定版リリースをダウンロードします。
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz
tar xvpzf hadoop-2.10.1.tar.gz
6. 次に、図に示すように ~/.bashrc ファイルに Hadoop 環境変数を追加します。
HADOOP_PREFIX=/root/hadoop-2.10.1
PATH=$PATH:$HADOOP_PREFIX/bin
export PATH JAVA_HOME HADOOP_PREFIX
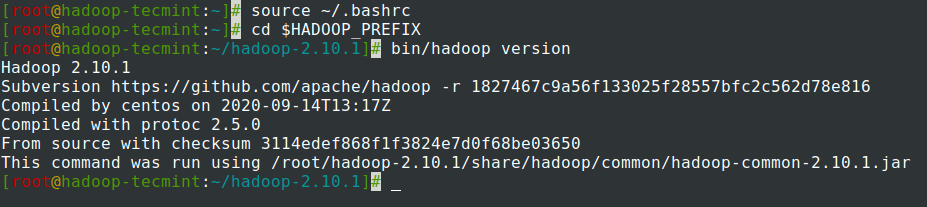
7. ファイルの ~/.bashrc に環境変数を追加した後、ファイルを取得し、次のコマンドを実行して Hadoop を確認します。
source ~/.bashrc
cd $HADOOP_PREFIX
bin/hadoop version
CentOS 7 での Hadoop の構成
マシンに適合させるには、以下の Hadoop 構成ファイルを構成する必要があります。 Hadoop では、各サービスに独自のポート番号と、データを保存するための独自のディレクトリがあります。
- Hadoop 構成ファイル – core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
8. まず、図に示すように、hadoop-env.sh ファイル内の JAVA_HOME と Hadoop パスを更新する必要があります。 。
cd $HADOOP_PREFIX/etc/hadoop
vi hadoop-env.sh
ファイルの先頭に次の行を入力します。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0/jre
export HADOOP_PREFIX=/root/hadoop-2.10.1
9. 次に、core-site.xml ファイルを変更します。
cd $HADOOP_PREFIX/etc/hadoop
vi core-site.xml
図のように、<configuration> タグの間に以下を貼り付けます。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
10. tecmint ユーザー ホーム ディレクトリの下に以下のディレクトリを作成します。これは NN および DN ストレージに使用されます。
mkdir -p /home/tecmint/hdata/
mkdir -p /home/tecmint/hdata/data
mkdir -p /home/tecmint/hdata/name
10. 次に、hdfs-site.xml ファイルを変更します。
cd $HADOOP_PREFIX/etc/hadoop
vi hdfs-site.xml
図のように、<configuration> タグの間に以下を貼り付けます。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/tecmint/hdata/name</value>
</property>
<property>
<name>dfs .datanode.data.dir</name>
<value>home/tecmint/hdata/data</value>
</property>
</configuration>
11. 再度、mapred-site.xml ファイルを変更します。
cd $HADOOP_PREFIX/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
図のように、<configuration> タグの間に以下を貼り付けます。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
12. 最後に、yarn-site.xml ファイルを変更します。
cd $HADOOP_PREFIX/etc/hadoop
vi yarn-site.xml
図のように、<configuration> タグの間に以下を貼り付けます。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
NameNode を使用した HDFS ファイル システムのフォーマット
13. クラスタを開始する前に、Hadoop NN がインストールされているローカル システムで Hadoop NN をフォーマットする必要があります。通常、これはクラスターを初めて起動する前の初期段階で行われます。
NN をフォーマットすると NN メタストア内のデータが失われるため、より慎重になる必要があります。意図的に必要でない限り、クラスターの実行中に NN をフォーマットしないでください。
cd $HADOOP_PREFIX
bin/hadoop namenode -format
14. NameNode デーモンと DataNode デーモンを開始します: (ポート 50070)。
cd $HADOOP_PREFIX
sbin/start-dfs.sh

15. ResourceManager デーモンと NodeManager デーモンを開始します: (ポート 8088)。
sbin/start-yarn.sh

16. すべてのサービスを停止します。
sbin/stop-dfs.sh
sbin/stop-dfs.sh
まとめ
まとめ
て この記事では、Hadoop 擬似ノード (単一ノード) のクラスタをセットアップする手順を段階的に説明しました。 Linux の基本的な知識があり、次の手順に従えば、クラスターは 40 分で起動します。
これは、初心者がHadoop の学習と練習を開始するのに非常に役立ちます。また、Hadoop のこのバニラ バージョンは開発目的に使用できます。リアルタイム クラスターが必要な場合は、少なくとも 3 台の物理サーバーを用意するか、複数のサーバーを備えたクラウドをプロビジョニングする必要があります。