Linux での 20 の便利な egrep コマンド例
概要: このガイドでは、egrep コマンドの実際的な例のいくつかについて説明します。このガイドに従うと、 ユーザーは Linux でテキスト検索をより効率的に実行できるようになります。
必要な情報がログに見つからずにイライラしたことはありませんか?大規模なデータセットから必要な情報を抽出するのは、複雑で時間のかかる作業です。
オペレーティング システムが適切なツールを提供しない場合、事態は非常に困難になります。ここで、Linux があなたを救ってくれます。 Linux には、awk、sed、cut などのさまざまなテキスト フィルタリング ユーティリティが用意されています。
ただし、egrep は Linux でのテキスト処理に最も強力で一般的に使用されるユーティリティの 1 つであり、egrep コマンドの例をいくつか説明します。
Linux の egrep コマンドは、ファイル内の特定のパターンを検索して照合するために使用される grep コマンドのファミリーとして認識されます。これはgrep -E (grep 拡張正規表現) と同様に機能しますが、主に特定のファイルまたは行を検索したり、指定されたファイル内の行を出力したりします。
egrep コマンドの構文は次のとおりです。
egrep [OPTIONS] PATTERNS [FILES]
例を使用するために、次の内容を含むサンプル テキスト ファイルを作成してみましょう。
cat sample.txt

ここで、テキスト ファイルの準備ができていることがわかります。次に、日常的に使用できるいくつかの一般的な例について説明します。
1. 単一ファイル内のパターンを見つける方法
簡単なパターン マッチングの例から始めましょう。以下のコマンドを使用して、sample.txt ファイル内の文字列 professional を検索できます。
egrep professionals sample.txt

ここで、コマンドが指定されたパターンを含む行を出力していることがわかります。
2. ファイル内の一致したパターンを強調表示する方法
一致したパターンを強調表示することで、出力の情報をさらに増やすことができます。これを実現するには、egrep コマンドの --color オプションを使用します。たとえば、次のコマンドはテキスト professionals を赤色で強調表示します。
egrep --color=auto professionals sample.txt

ここでは、同じ出力が前の出力と比較してより有益であることがわかります。また、professionals という単語が 2 回繰り返されていることも簡単に識別できます。
ほとんどの Linux システムでは、次のエイリアスを使用して上記の設定がデフォルトで有効になります。
alias egrep='egrep –color=auto'
3. 複数のファイルからパターンを見つける方法
egrep コマンドは引数として複数のファイルを受け入れるため、複数のファイルで特定のパターンを検索できます。これを例で理解してみましょう。
まず、sample.txt ファイルのコピーを作成します。
cp sample.txt sample-copy.txt
次に、両方のファイルでパターン professionals を検索します。
egrep professionals sample.txt sample-copy.txt

上の例では、出力にファイル名が表示されます。これは、そのファイルの一致した行を表します。
4. ファイル内の一致する行を数える方法
場合によっては、ファイル内にパターンが存在するかどうかを確認するだけで十分な場合があります。 「はい」の場合、それは何行で表示されますか?このような場合は、コマンドの -c オプションを使用できます。
たとえば、次のコマンドでは、単語 professionals が 1 行にしか存在しないため、出力として 1 が表示されます。
egrep -c professionals sample.txt
1
5. ファイル内の一致した行のみを印刷する方法
前の例では、-c オプションがパターンの出現数をカウントしないことがわかりました。たとえば、単語 professionals が同じ行に 2 回出現しますが、-c オプションはそれを 1 つの一致としてのみ扱います。
このような場合、コマンドの -o オプションを使用して、一致したパターンのみを出力できます。たとえば、以下のコマンドは、単語 professionals を 2 つの別々の行に表示します。
egrep -o professionals sample.txt
ここで、wc コマンドを使用して行数を数えてみましょう。
egrep -o professionals sample.txt | wc -l

上の例では、egrep と wc コマンドの組み合わせを使用して、特定のパターンの出現数をカウントしました。
6. 大文字と小文字を無視してパターンを見つける方法
デフォルトでは、egrep は大文字と小文字を区別してパターン マッチングを実行します。これは単語を意味します。we、We、wE、WE は別の単語として扱われます。ただし、-i オプションを使用すると、大文字と小文字を区別しない検索を強制できます。
たとえば、以下のコマンドでは、テキスト we と We のパターン マッチが成功します。
egrep -i we sample.txt

7. 部分的に一致するパターンを除外する方法
前の例では、egrep コマンドが部分一致を実行することがわかりました。たとえば、テキスト we を検索すると、他のテキストでもパターン マッチングが成功しました。ウェブ、ウェブサイト、ワームなど。
この制限を克服するには、単語全体の一致を強制する -w オプションを使用できます。
egrep -w we sample.txt

8. ファイル内のパターンマッチングを反転する方法
これまでは、egrep コマンドを使用して、指定されたパターンが存在する行を出力しました。ただし、場合によっては、逆の方法で操作を実行したい場合があります。
たとえば、指定されたパターンが存在しない行を印刷したい場合があります。 -v オプションを使用すると、これを実現できます。
egrep -v we sample.txt

ここで、コマンドがテキスト we を含まないすべての行を出力していることがわかります。
9. パターンの行番号を確認する方法
コマンドの -n オプションを使用すると、行番号付けを有効にすることができます。これにより、パターン マッチングが成功したときに出力に行番号が表示されます。この簡単なトリックにより、出力がより意味のあるものになります。
egrep -n professionals sample.txt

上記の出力では、単語 professionals が 5 行目にあることがわかります。
10. Quiet モードでパターン マッチングを実行する方法
Quiet モードでは、egrep コマンドは一致したパターンを出力しません。したがって、コマンドの戻り値を使用して、パターン マッチングが成功したかどうかを識別する必要があります。
コマンドの -q オプションを使用すると、Quiet モードを有効にすることができます。これは、シェル スクリプトを作成するときに便利です。
egrep -q professionals sample.txt
egrep -q non-existing-pattern sample.txt

この例では、 戻り値ゼロはパターンの存在を示し、ゼロ以外の値はパターンの不在を示します。
11. パターンマッチ前の行を表示する方法
場合によっては、一致したパターンの周囲に数行を表示することが合理的です。このようなシナリオでは、コマンドの -B オプションを使用すると、一致したパターンの N 行前を表示します。
たとえば、以下のコマンドは、パターン一致が成功した行とその 2 行前の行を出力します。
egrep -B 2 -n professionals sample.txt

この例では、 -n オプションを使用して行番号を表示しています。
12. パターンマッチ後の行の表示方法
同様の方法で、コマンドの -A オプションを使用して、パターン一致後の行を表示できます。たとえば、以下のコマンドは、パターン一致が成功した行と次の 2 行を出力します。
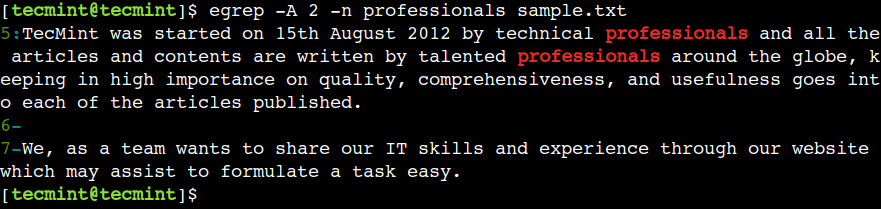
egrep -A 2 -n professionals sample.txt
13. パターンマッチの周囲の線を表示する方法
これに加えて、egrep コマンドは、オプション -A と -B< の機能を組み合わせた は、一致したパターンの前後の行を表示します。-C オプションをサポートします。
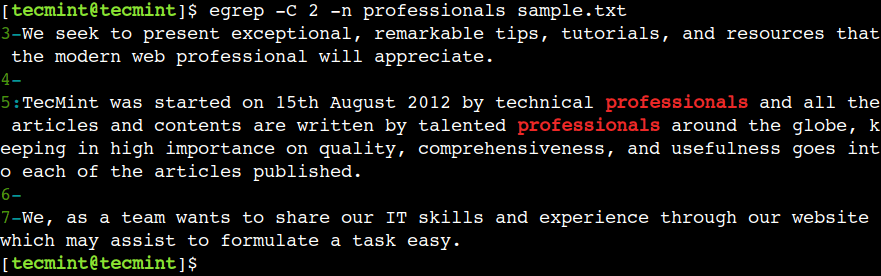
egrep -C 2 -n professionals sample.txt
14. 複数のファイルからパターンを再帰的に見つける方法
前に説明したように、複数のファイルに対してパターン マッチングを実行できます。ただし、ファイルが複数のサブディレクトリに存在し、それらすべてをコマンド引数として渡す場合、状況は複雑になります。
このような場合、次の例に示すように、-r オプションを使用してパターン マッチングを再帰的に実行できます。
まず、2 つのサブディレクトリを作成し、sample.txt ファイルをそれらのディレクトリにコピーします。
mkdir -p dir1/dir2
cp sample.txt dir1/
cp sample.txt dir1/dir2/
次に、再帰的な方法で検索操作を実行してみましょう。
egrep -r professionals dir1

上の例では、dir1/dir2/sample.txt ファイルと dir1/sample.txt ファイルのパターン マッチが成功したことがわかります。
15. 正規表現を使用して単一の文字を一致させる方法
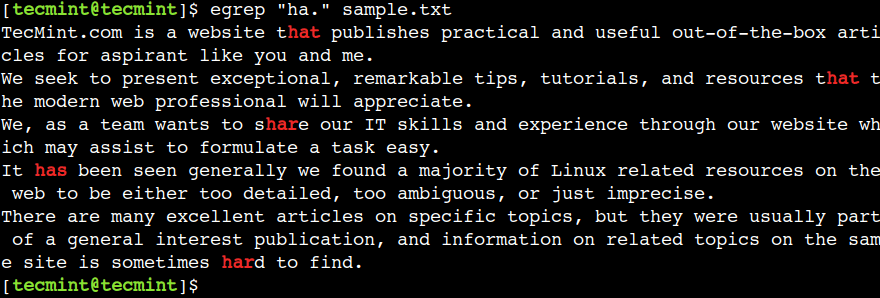
ドット (.) 文字を使用して、行末を除く任意の 1 文字と一致させることができます。たとえば、次の正規表現は、テキスト har、hat、および has と一致します。
egrep "ha." sample.txt
16. ゼロ個以上の文字の出現を一致させる方法
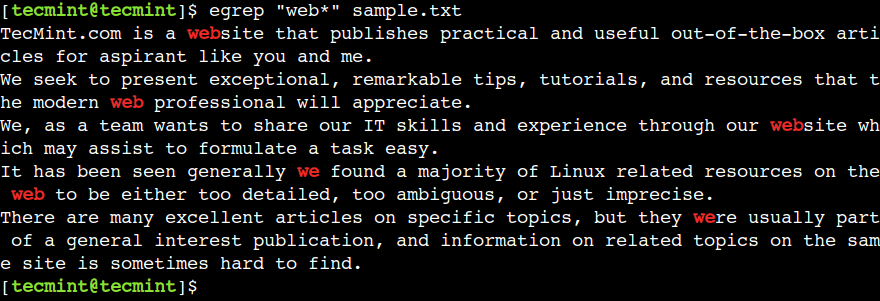
アスタリスク (*) を使用すると、前の文字の 0 個以上の出現と一致します。たとえば、次の正規表現は、文字列 we の後にゼロ個以上の文字 b が続くテキストと一致します。
egrep "web*" sample.txt
17. 前の文字の 1 つ以上の出現を一致させる方法
プラス (+) を使用して、前の文字の 1 つ以上の出現と一致させることができます。たとえば、次の正規表現は、文字列 we の後に文字 b が少なくとも 1 回出現するテキストと一致します。
egrep "web+" sample.txt
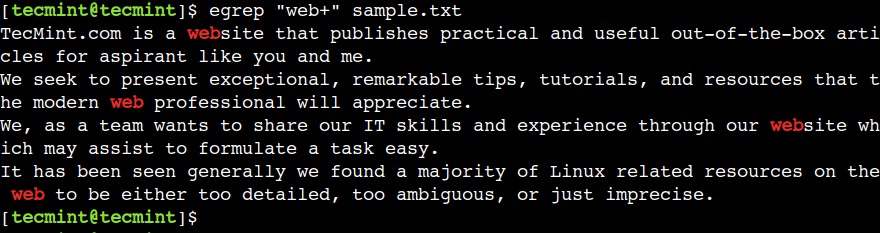
ここでは、文字 b が存在しないため、単語 we と were ではパターン マッチングが成功しないことがわかります。
18. 行頭の合わせ方
キャレット (^) を使用して行の先頭を表すことができます。たとえば、次の正規表現は、テキスト We で始まる行を出力します。
egrep "^We" sample.txt

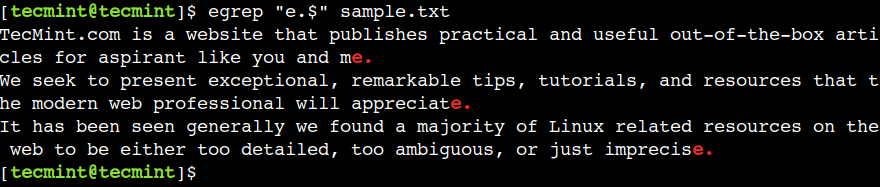
19. 行末を一致させる方法
ドルの ($) を使用して行の終わりを表すことができます。たとえば、以下の正規表現は、テキスト e. で終わる行を出力します。
egrep "e.$" sample.txt
20. ファイル内の空行を削除する方法
キャレット (^) の直後にドル ($) を使用して空の行を表すことができます。これを正規表現で使用して空行を削除してみましょう。
egrep -n -v "^$" sample.txt
![]()
上記の出力では、行番号 2、4、6、8、10 が空であるため表示されていないことがわかります。
結論
この記事では、egrep コマンドの役立つ例をいくつか説明しました。これらの例を日常生活で使用して、生産性を向上させることができます。
Linux の egrep コマンドの他の最良の例を知っていますか?以下のコメント欄であなたのご意見をお聞かせください。