Ubuntu/Debian に Apache Spark をインストールしてセットアップする方法
Apache Spark は、より高速な計算結果を提供するために作成されたオープンソースの分散計算フレームワークです。これはインメモリ計算エンジンであり、データはメモリ内で処理されることを意味します。
Spark は、ストリーミング、グラフ処理、SQL、MLLib 用のさまざまな API をサポートしています。また、Java、Python、Scala、R も優先言語としてサポートされています。 Spark は主に Hadoop クラスターにインストールされますが、スタンドアロン モードで Spark をインストールして構成することもできます。
この記事では、Debian およびUbuntu ベースのディストリビューションにApache Spark をインストールする方法について説明します。
UbuntuにJavaとScalaをインストールする
Ubuntu にApache Spark をインストールするには、 マシンにJava と Scala がインストールされている必要があります。最新のディストリビューションのほとんどには、デフォルトで Java がインストールされており、次のコマンドを使用して確認できます。
java -version

出力がない場合は、Ubuntu に Java をインストールする方法に関する記事を使用して Java をインストールするか、次のコマンドを実行して Ubuntu および Debian ベースのディストリビューションに Java をインストールできます。
sudo apt update
sudo apt install default-jre
java -version
次に、次のコマンドを実行して scala を検索し、インストールすることで、apt リポジトリからScala をインストールできます。
sudo apt search scala ⇒ Search for the package
sudo apt install scala ⇒ Install the package
Scala のインストールを確認するには、次のコマンドを実行します。
scala -version
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
UbuntuにApache Sparkをインストールする
次に、公式の Apache Spark ダウンロード ページにアクセスし、この記事の執筆時点での最新バージョン (つまり 3.1.1) を入手します。あるいは、wget コマンドを使用して、ターミナルにファイルを直接ダウンロードすることもできます。
wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
次に、ターミナルを開き、ダウンロードしたファイルが配置されている場所に切り替えて、次のコマンドを実行して Apache Spark tar ファイルを抽出します。
tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz
最後に、 抽出した Spark ディレクトリを /opt ディレクトリに移動します。
sudo mv spark-3.1.1-bin-hadoop2.7 /opt/spark
Spark の環境変数を構成する
ここで、Spark を起動する前に、.profile ファイルにいくつかの環境変数を設定する必要があります。
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
これらの新しい環境変数がシェル内で到達可能であり、Apache Spark で使用できることを確認するには、次のコマンドを実行して最近の変更を有効にすることも必須です。
source ~/.profile
サービスを開始および停止するためのすべての Spark 関連のバイナリは、sbin フォルダの下にあります。
ls -l /opt/spark
UbuntuでApache Sparkを起動する
次のコマンドを実行してSpark マスター サービスとスレーブ サービスを開始します。
start-master.sh
start-workers.sh spark://localhost:7077

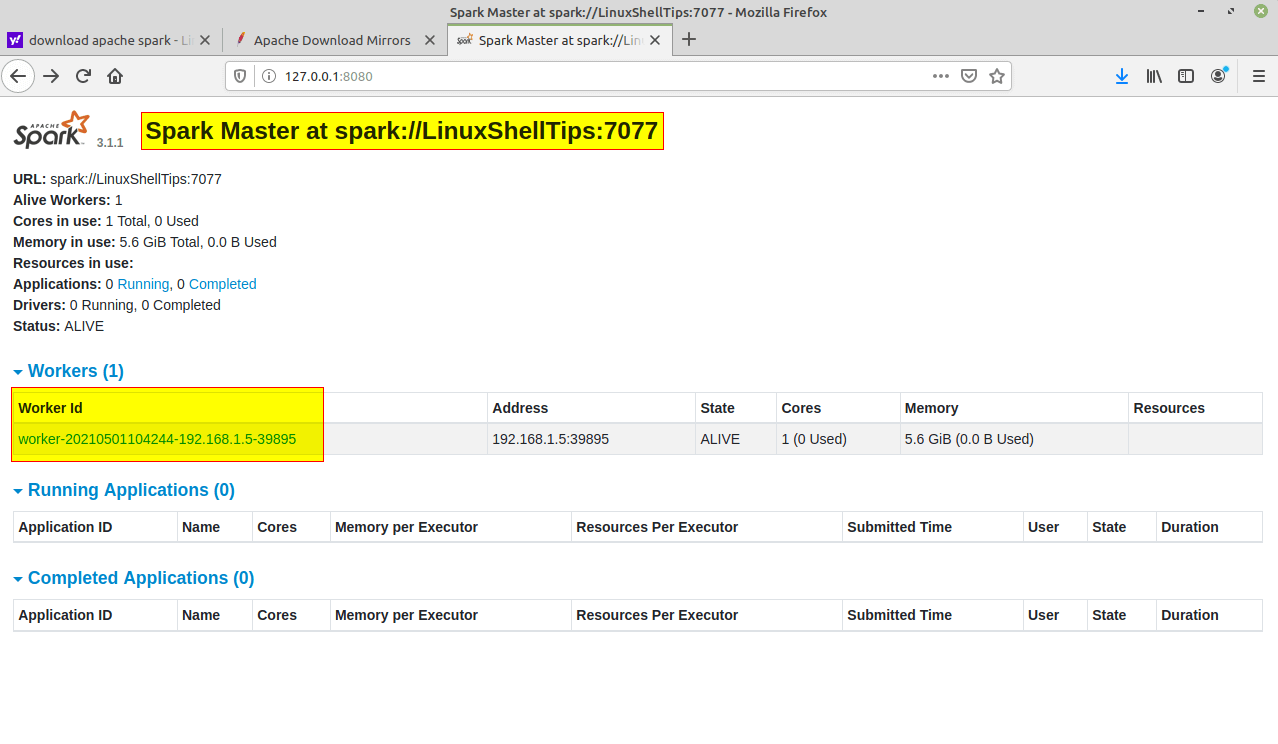
サービスが開始されたら、ブラウザに移動して次の URL を入力し、Spark ページにアクセスします。ページから、マスターとスレーブのサービスが開始されていることがわかります。
http://localhost:8080/
OR
http://127.0.0.1:8080
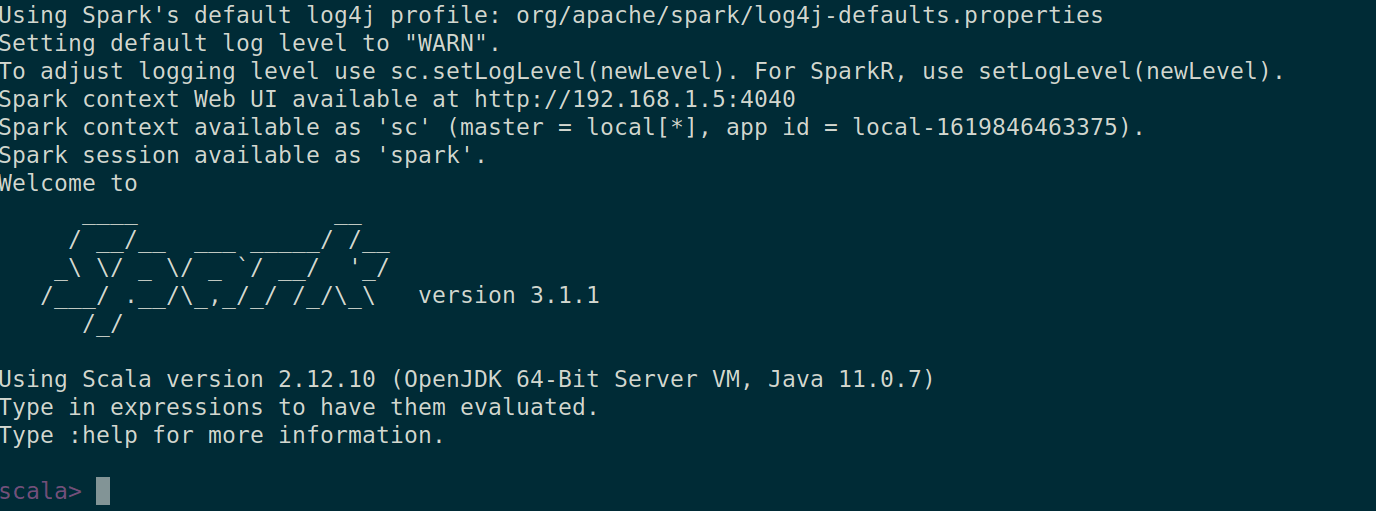
spark-shell コマンドを起動して、spark-shell が正常に動作するかどうかを確認することもできます。
spark-shell
この記事はここまでです。近いうちに別の興味深い記事をお届けする予定です。