データを回復し、障害が発生したソフトウェア RAID を再構築する方法 - パート 8
この RAID シリーズの前の記事では、ゼロから RAID ヒーローまで成長しました。いくつかのソフトウェア RAID 構成を検討し、それぞれの構成の要点と、特定のシナリオに応じてどちらか一方に頼る理由を説明しました。

このガイドでは、ディスク障害が発生した場合にデータを失わずにソフトウェア RAID アレイを再構築する方法について説明します。簡潔にするために、 ここではRAID 1 セットアップのみを考慮しますが、概念とコマンドはすべてのケースに同様に適用されます。
RAID テストのシナリオ
先に進む前に、このシリーズのパート 3「Linux で RAID 1 (ミラー) をセットアップする方法」 に記載されている手順に従ってRAID 1 アレイをセットアップしていることを確認してください。
現在のケースでの唯一のバリエーションは次のとおりです。
1) その記事で使用されているバージョン (v6.5) とは異なるバージョンの CentOS (v7)、および
/dev/sdb と /dev/sdc では 2) 異なるディスク サイズ (それぞれ 8 GB)。
さらに、SELinux が強制モードで有効になっている場合は、RAID デバイスをマウントするディレクトリに対応するラベルを追加する必要があります。そうしないと、マウントしようとすると次の警告メッセージが表示されます。
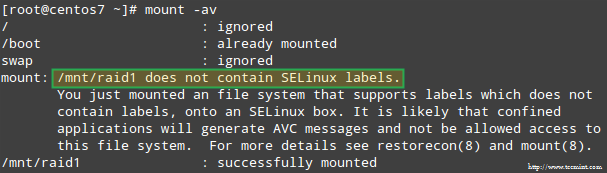
これを修正するには、次のコマンドを実行します。
restorecon -R /mnt/raid1
RAID監視の設定
ストレージ デバイスに障害が発生する理由はさまざまですが (ただし、SSD によりこの障害が発生する可能性は大幅に減少しました)、原因に関係なく、問題はいつでも発生する可能性があるため、障害が発生したデバイスを交換する準備をしておく必要があります。データの可用性と整合性を確保するためです。
最初に一言アドバイス。 RAID のステータスをチェックするために /proc/mdstat を検査できる場合でも、モニターとスキャンで mdadm を実行するという、より優れた時間を節約する方法があります。モードでは、事前定義された受信者に電子メールでアラートが送信されます。
これを設定するには、/etc/mdadm.conf に次の行を追加します。
MAILADDR user@<domain or localhost>
私の場合:
MAILADDR gacanepa@localhost

モニター + スキャン モードで mdadm を実行するには、root として次の crontab エントリを追加します。
@reboot /sbin/mdadm --monitor --scan --oneshot
デフォルトでは、mdadm は 60 秒ごとに RAID アレイをチェックし、問題が見つかった場合はアラートを送信します。この動作を変更するには、上記の crontab エントリに --lay オプションを秒数とともに追加します (たとえば、--lay 1800 は 30 分を意味します)。
最後に、mutt や mailx などのメール ユーザー エージェント (MUA) がインストールされていることを確認してください。そうしないと、アラートは受信されません。
すぐに、mdadm によって送信されるアラートがどのようなものかを見てみましょう。
故障した RAID ストレージデバイスのシミュレーションと交換
RAID アレイ内のストレージ デバイスの 1 つに関する問題をシミュレートするには、次のように --manage オプションと --set-faulty オプションを使用します。
mdadm --manage --set-faulty /dev/md0 /dev/sdc1
これにより、/proc/mdstat でわかるように、/dev/sdc1 が障害があるとマークされます。
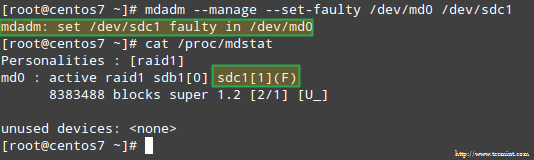
さらに重要なのは、同じ警告を含む電子メール アラートを受信したかどうかを確認してみましょう。

この場合、ソフトウェア RAID アレイからデバイスを削除する必要があります。
mdadm /dev/md0 --remove /dev/sdc1
次に、マシンから物理的に取り外して、スペアパーツ (/dev/sdd、fd タイプのパーティションが事前に作成されている場所) と交換できます。
mdadm --manage /dev/md0 --add /dev/sdd1
幸いなことに、システムは追加した部分を使用してアレイの再構築を自動的に開始します。これをテストするには、/dev/sdb1 を障害があるとマークし、アレイから削除し、tecmint.txt ファイルがまだ / でアクセスできることを確認します。 mnt/raid1:
mdadm --detail /dev/md0
mount | grep raid1
ls -l /mnt/raid1 | grep tecmint
cat /mnt/raid1/tecmint.txt

上の画像は、/dev/sdc1 の代わりに /dev/sdd1 をアレイに追加した後、データの再構築が介入なしでシステムによって自動的に実行されたことを明確に示しています。私たちの側では。
厳密には必須ではありませんが、障害のあるデバイスを正常なドライブに交換するプロセスをすぐに実行できるように、予備のデバイスを用意しておくことをお勧めします。これを行うには、/dev/sdb1 と /dev/sdc1 を再度追加しましょう。
mdadm --manage /dev/md0 --add /dev/sdb1
mdadm --manage /dev/md0 --add /dev/sdc1

冗長性の喪失からの回復
前に説明したように、1 つのディスクに障害が発生した場合、mdadm はデータを自動的に再構築します。しかし、アレイ内の 2 つのディスクに障害が発生した場合はどうなるのでしょうか? /dev/sdb1 と /dev/sdd1 を障害があるとしてマークして、このようなシナリオをシミュレートしてみましょう。
umount /mnt/raid1
mdadm --manage --set-faulty /dev/md0 /dev/sdb1
mdadm --stop /dev/md0
mdadm --manage --set-faulty /dev/md0 /dev/sdd1
この時点で作成されたのと同じ方法 (または --assume-clean オプションを使用) で配列を再作成しようとすると、データが失われる可能性があるため、最後の手段として残しておく必要があります。
たとえば、/dev/sdb1 から同様のディスク パーティション (/dev/sde1) にデータを復元してみます。これには、次のパーティションを作成する必要があることに注意してください。続行する前に、/dev/sde に fd と入力します)。ddrescue を使用します。
ddrescue -r 2 /dev/sdb1 /dev/sde1
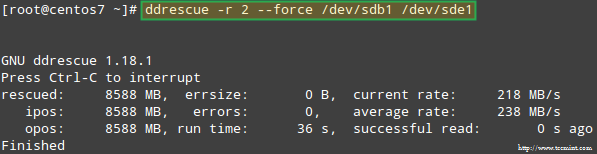
この時点まで、RAID アレイの一部であるパーティションである /dev/sdb または /dev/sdd には触れていないことに注意してください。
次に、/dev/sde1 と /dev/sdf1 を使用して配列を再構築しましょう。
mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
実際の状況では、通常、元のアレイと同じデバイス名、つまり、/dev/sdb1 と /dev/sdc1 をその後に使用することに注意してください。障害が発生したディスクは新しいディスクに交換されました。
この記事では、新しいディスクでアレイを再作成し、元の障害が発生したドライブとの混乱を避けるために、追加のデバイスを使用することにしました。
配列の書き込みを続行するかどうかを尋ねられたら、Y と入力してEnter を押します。アレイが開始され、次のように進行状況を監視できるはずです。
watch -n 1 cat /proc/mdstat
プロセスが完了すると、RAID のコンテンツにアクセスできるようになります。
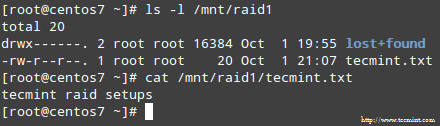
まとめ
この記事ではRAIDの障害と冗長性の喪失から回復する方法を確認しました。ただし、このテクノロジーはストレージ ソリューションであり、 バックアップに代わるものではないことに留意する必要があります。
このガイドで説明されている原則は、すべての RAID セットアップに同様に適用されます。また、このシリーズの次の最後のガイド (RAID 管理) で取り上げる概念も同様です。
この記事に関してご質問がございましたら、以下のコメント フォームを使用してお気軽にお問い合わせください。お返事おまちしております!