高可用性を備えた Hive をインストールおよび構成する方法 – パート 7
Hive はHadoop エコシステムのデータ ウェアハウスモデルです。これはHadoop 上の ETL ツールとして実行できます。 Hive で高可用性 (HA) を有効にすることは、Namenode や Resource Manager などのマスター サービスで行うこととは異なります。
Hive (Hiveserver2) では自動フェイルオーバーは発生しません。いずれかの Hiveserver2 (HS2) が失敗すると、その失敗した HS2 で実行中のジョブは失敗します。ジョブを他のHiveServer2で実行できるように、ジョブを再送信する必要があります。したがって、HS2 で HA を有効にすることは、クラスタ内のHS2コンポーネントの数を増やすことに他なりません。
この記事では、Hive の高可用性をインストールして有効にする手順について説明します。
要件
- CentOS/RHEL 7 に Hadoop サーバーを導入するためのベスト プラクティス – パート 1
- Hadoop の前提条件のセットアップとセキュリティ強化 - パート 2
- CentOS/RHEL 7 に Cloudera Manager をインストールして構成する方法 – パート 3
- CentOS/RHEL 7 に CDH をインストールしてサービス プレースメントを構成する方法 – パート 4
- Namenode の高可用性をセットアップする方法 – パート 5
- Resource Manager の高可用性をセットアップする方法 – パート 6
始めましょう…
Hive のインストールと構成
1. 以下の URL で Cloudera Manager にログインし、Cloudera Manager –> Add Service に移動します。 です。
http://13.233.129.39:7180/cmf/home
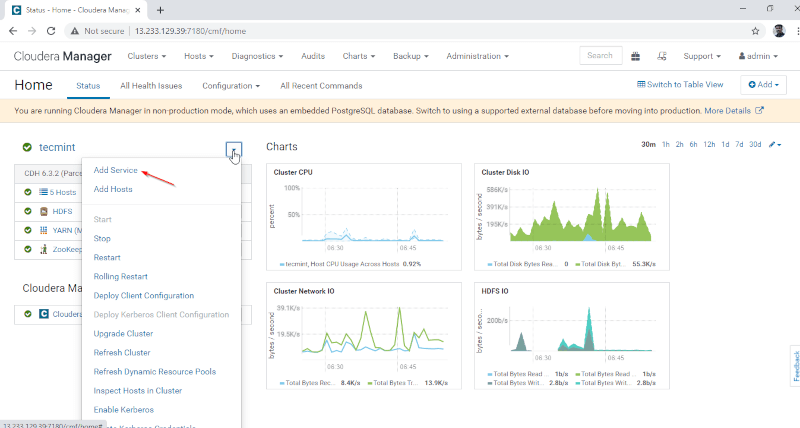
2. サービス「Hive」を選択します。
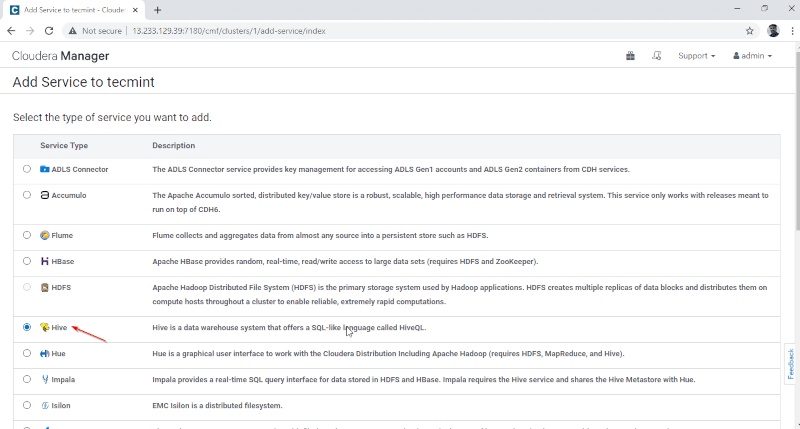
3. ノードにサービスを割り当てます。
- ゲートウェイ – ユーザーが Hive にアクセスできるクライアント サービスです。通常、このサービスはユーザー専用のエッジノードに配置されます。
- Hive メタストア – Hive メタデータを保存するための中央リポジトリです。
- WebHCat サーバー – HCatalog およびその他の Hadoop サービス用の Web API です。
- Hiveserver2 – Hive でクエリを実行するためのクライアントのインターフェイスです。
サーバーを選択したら、[続行] をクリックして続行します。
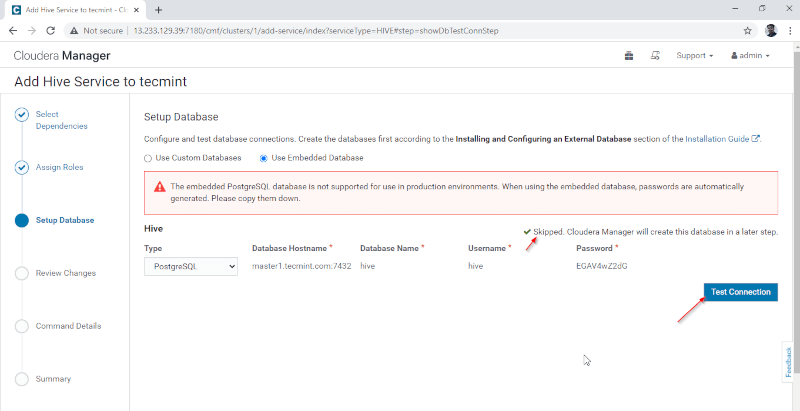
4. Hive Metastore には、メタデータを保存するための基盤となるデータベースが必要です。ここでは、CDH が組み込まれているデフォルトの PostgreSQL データベースを使用しています。
以下に示すデータベースの詳細は自動的に入力されます。前述のデータベースはその場で作成されるため、「接続のテスト」はスキップされます。リアルタイムで、外部データベースにデータベースを作成し、接続をテストして次に進む必要があります。完了したら、[続行] をクリックしてください。
5. Hive Warehouse ディレクトリを構成します。/user/hive/warehouse は、Hive テーブルを保存するためのデフォルトのディレクトリ パスです。 [続行] をクリックします。
6. Hive のインストールが開始されます。
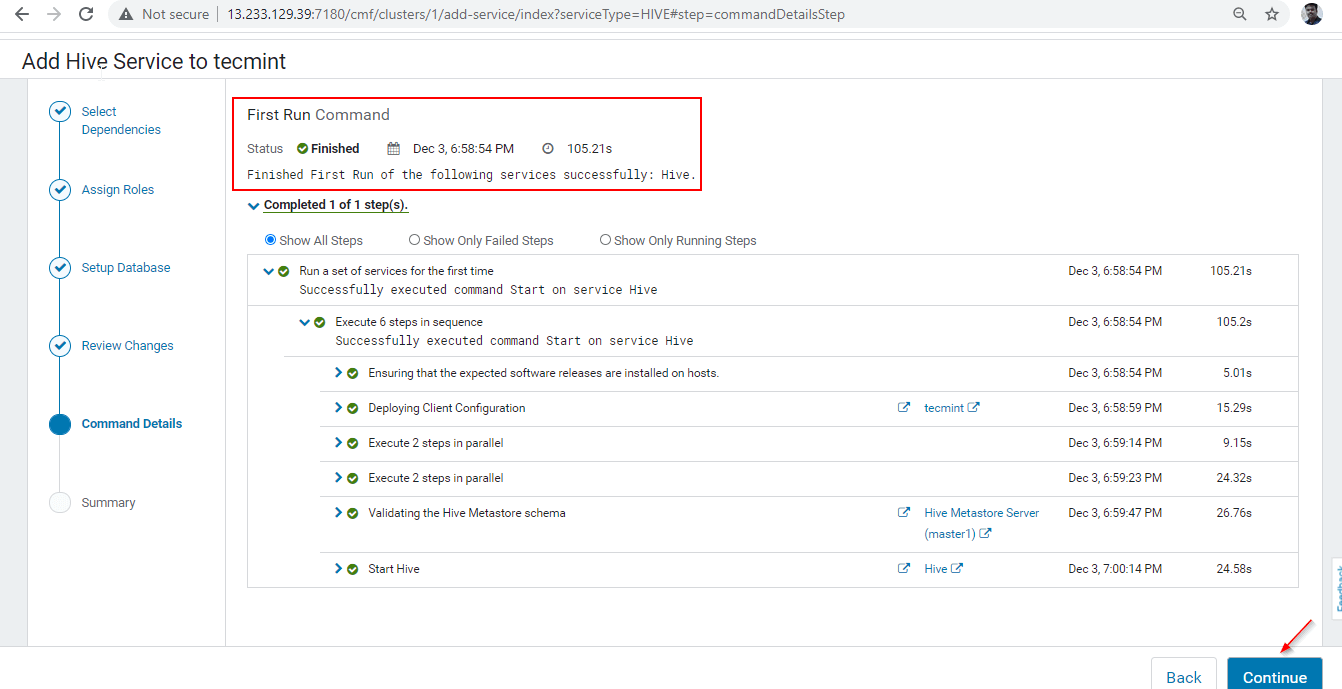
7. インストールが完了すると、「完了」ステータスが表示されます。 [続行] をクリックして次に進みます。
8. Hive のインストールと構成は正常に完了しました。 [完了] をクリックしてインストール手順を完了します。
9. Cloudera Manager ダッシュボードを通じて、クラスタに追加されたHiveサービスを確認できます。

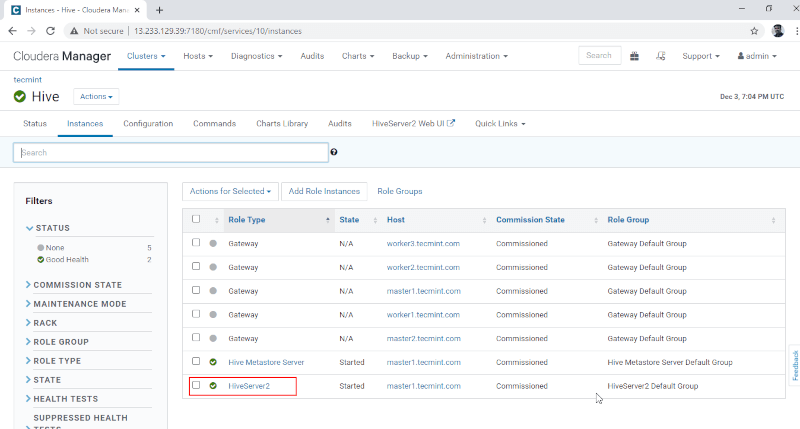
10. Hive のインスタンスで Hiveserver2 を表示できます。 マスター 1 に Hiveserver2 を追加しました。
Cloudera マネージャー –> ハイブ –> インスタンス –> Hiveserver2。
Hive での高可用性の有効化
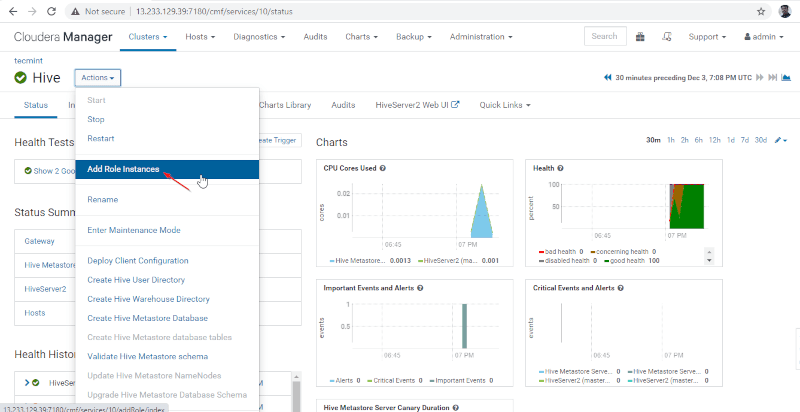
11. 次に、Cloudera Manager –> Hive –> Actions –> に移動して、Hive ロールを追加します。ロールインスタンスを追加します。
12. 追加の Hiveserver2 を配置するサーバーを選択します。 2 つ以上追加できます。制限はありません。ここでは、master2 にもう 1 つの Hiveserver2 を追加しています。

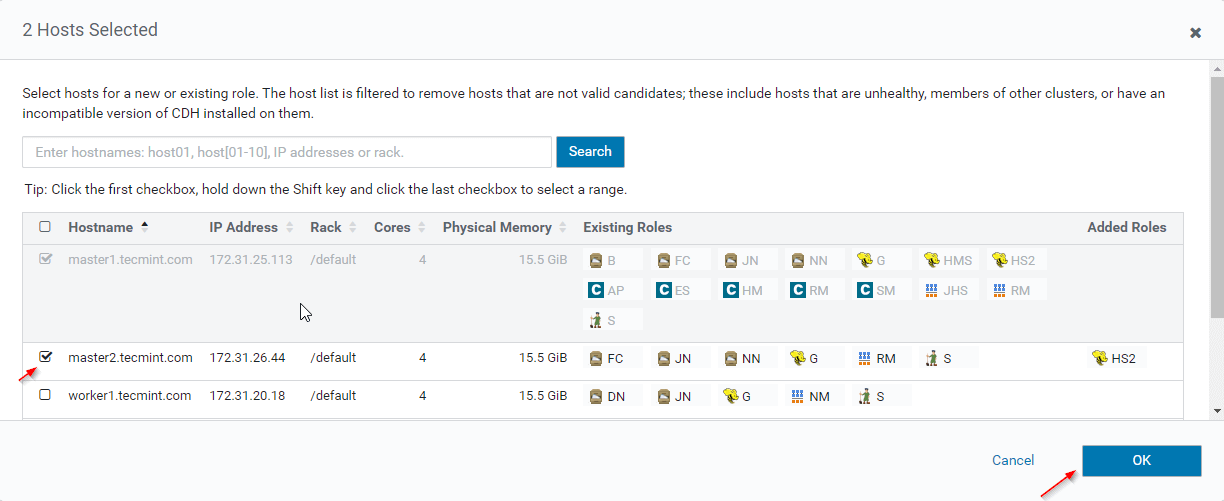
13. サーバーを選択したら、[続行] をクリックします。

14. Hiverserver2 が Hive インスタンスに追加されます。Cloudera Manager に移動して起動する必要があります。 –> Hive –> インスタンス –> (選択 Hiveserver2 が新しく追加されました) –> 選択されたものに対するアクション –> スタートします。
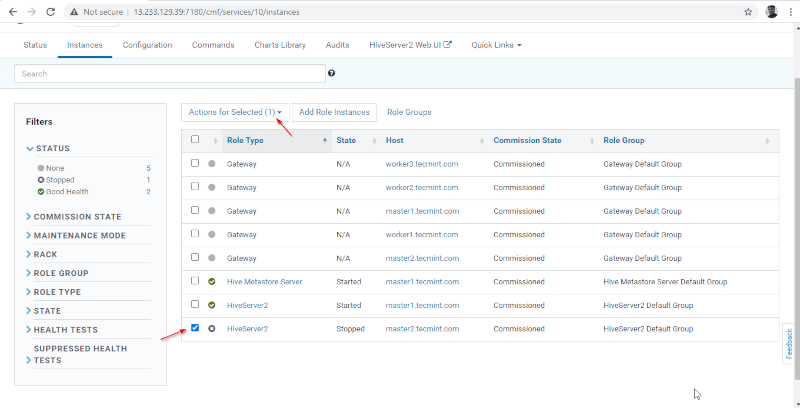


15. マスター 2 で Hiveserver2 が開始されると、ステータスが「完了」になります。 [閉じる] をクリックします。

16. 両方の Hiveserver2 が実行されていることがわかります。
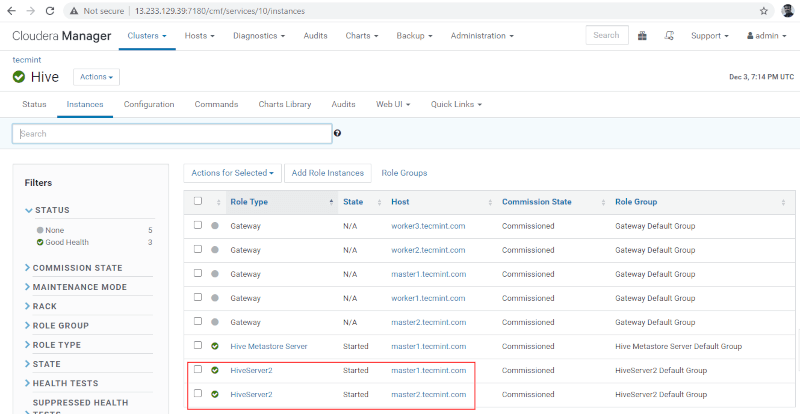
Hive の可用性の確認
シンクライアントとコマンドラインである beeline を介してHiveserver2 に接続できます。 JDBC ドライバーを使用して接続を確立します。
17. Hive ゲートウェイ が実行されているサーバーにログインします。
[tecmint@master1 ~]$ beeline

18. JDBC 接続文字列を入力して Hiveserver2 に接続します。これに関連して、 ここで言及している文字列は、デフォルトのポート番号が10000のHiverserver2 (master2) です。この接続文字列は、マスター 2 で実行されている Hiveserver2 にのみ接続します。
beeline> !connect "jdbc:hive2://master1.linux-console.net:10000"

19. サンプル クエリを実行します。
0: jdbc:hive2://master1.linux-console.net:10000> show databases;
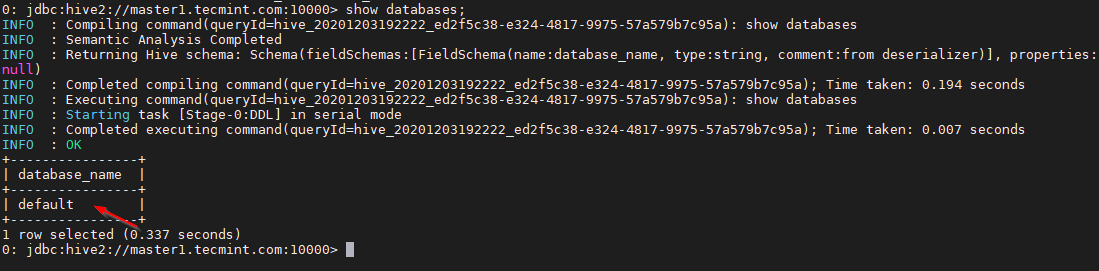
これは、組み込まれているデフォルトのデータベースです。
20. 以下のコマンドを使用して、Hive セッションを終了します。
0: jdbc:hive2://master1.linux-console.net:10000> !quit

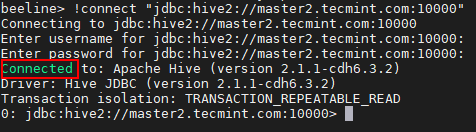
21. 同じ方法を使用して、master2 で実行されている Hiveserver2 に接続できます。
beeline> !connect "jdbc:hive2://master2.linux-console.net:10000"
23. Zookeeper Discovery モードで Hiveserver2 に接続できます。この方法では、接続文字列で Hiveserver2 を指定する必要はなく、代わりに Zookeeper を使用して利用可能な Hiveserver2 を検出します。
ここでは、サードパーティのロード バランサーを使用して、利用可能なHiverserver2 間で負荷のバランスをとります。以下の設定は、Cloudera Manager –> Hive –> Configuration に移動して Zookeeper Discovery Mode を有効にする必要があります。

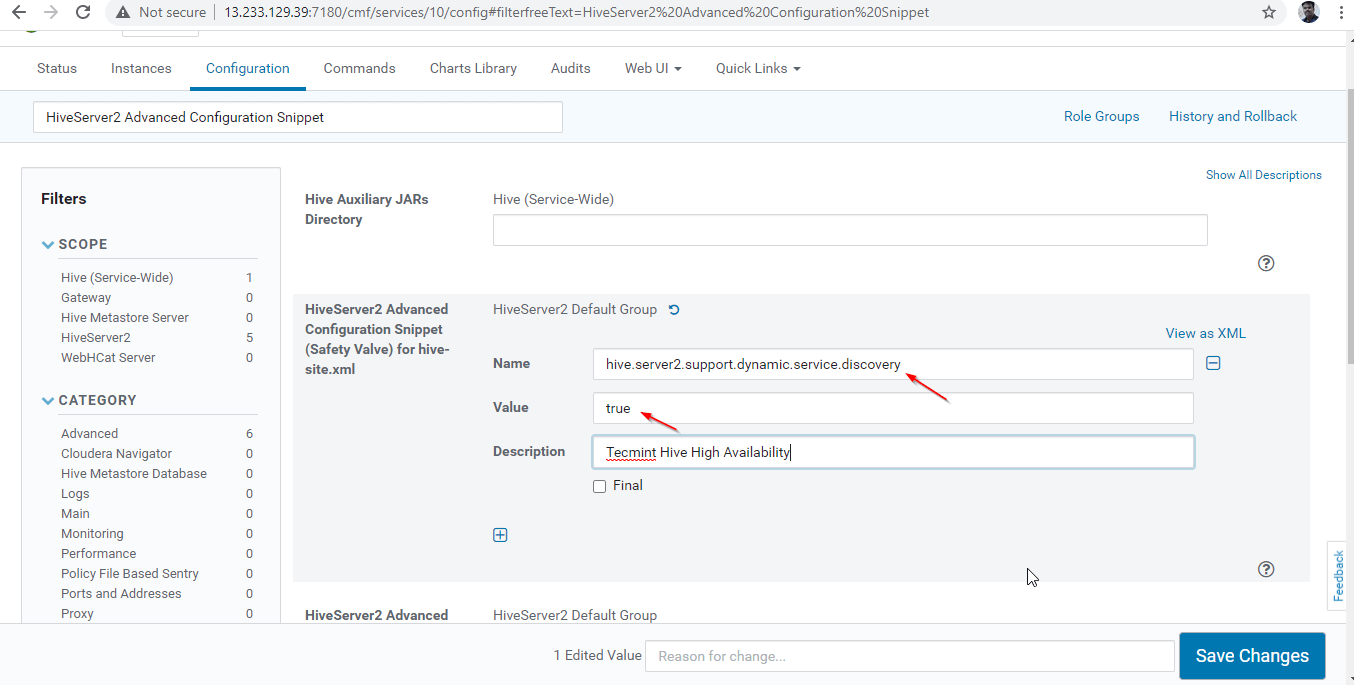
24. 次に、プロパティ「HiveServer2 Advanced Configuration Snippet」を検索し、+ 記号をクリックして以下のプロパティを追加します。
Name : hive.server2.support.dynamic.service.discovery
Value : true
Description : <any description>

25. プロパティを入力したら、[変更を保存] をクリックします。
26. 構成に変更を加えたので、オレンジ色のシンボルをクリックしてサービスを再起動し、影響を受けるサービスを再起動する必要があります。
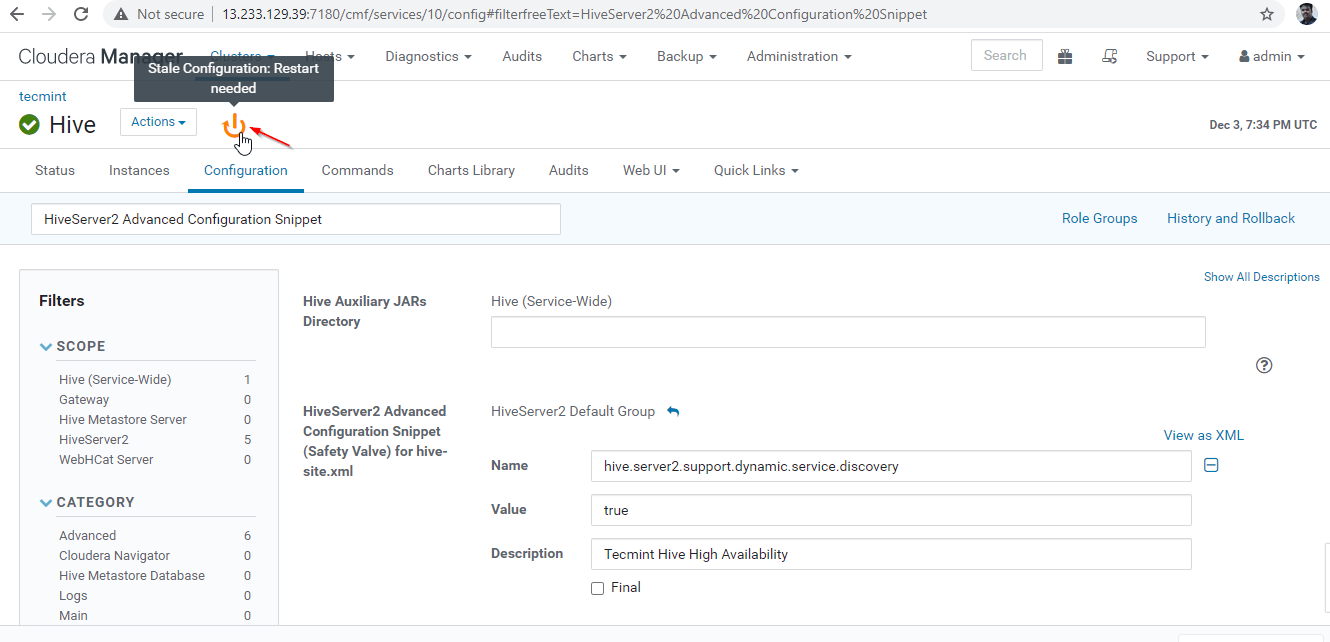
27. [古いサービスを再起動する] をクリックします。
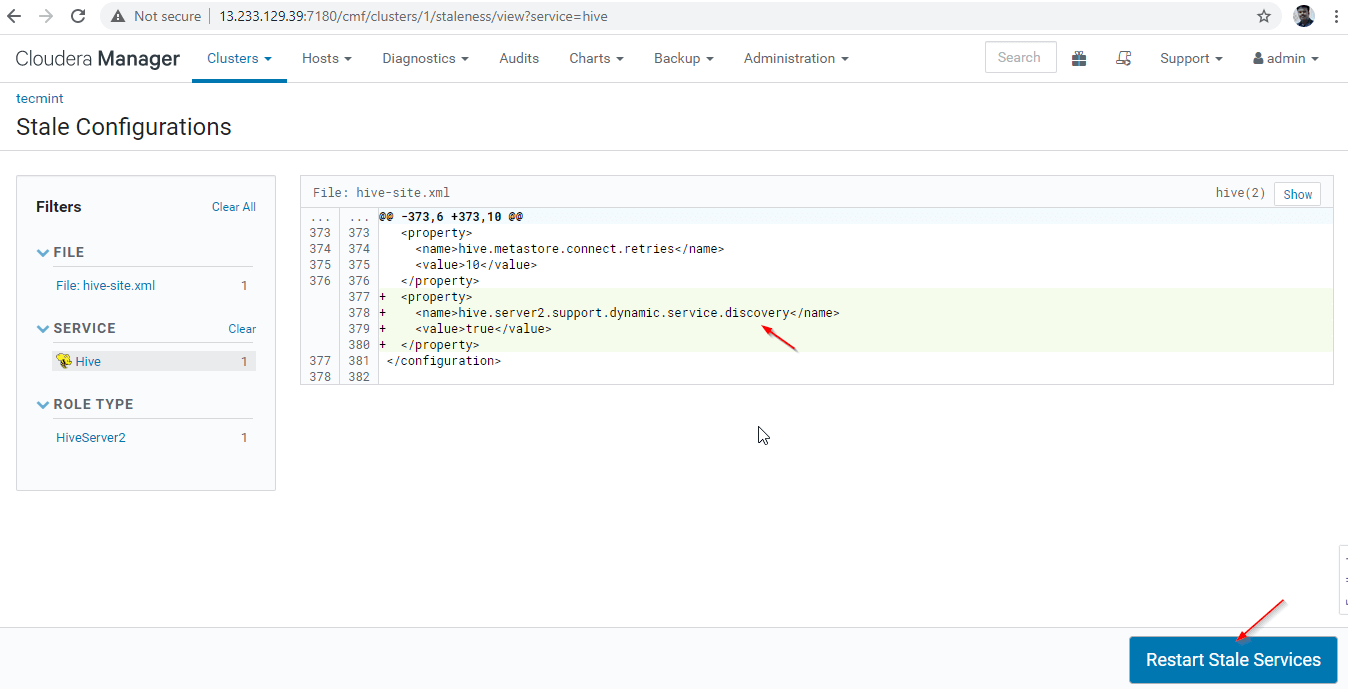
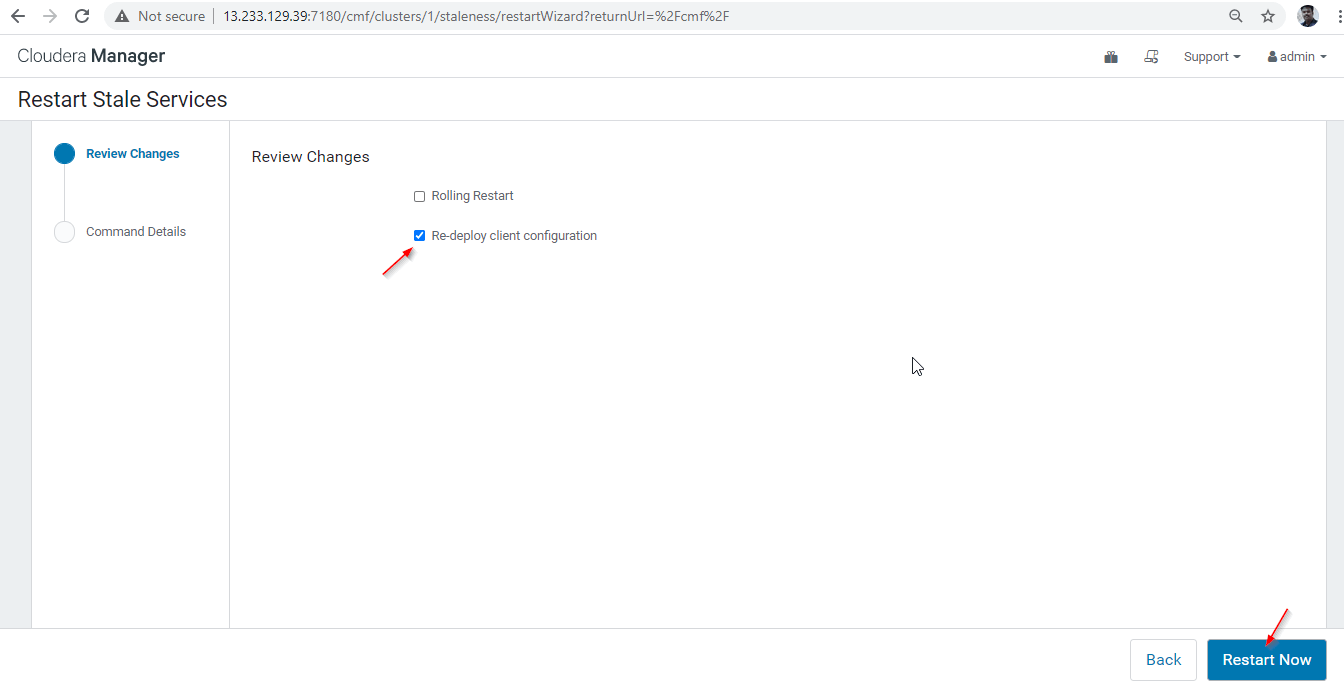
28. 利用可能なオプションは 2 つあります。クラスターが運用中の場合は、停止を最小限に抑えるためにローリング再起動を優先する必要があります。新しくインストールするので、2 番目のオプション [クライアント構成を再展開] を選択し、[今すぐ再起動] をクリックします。
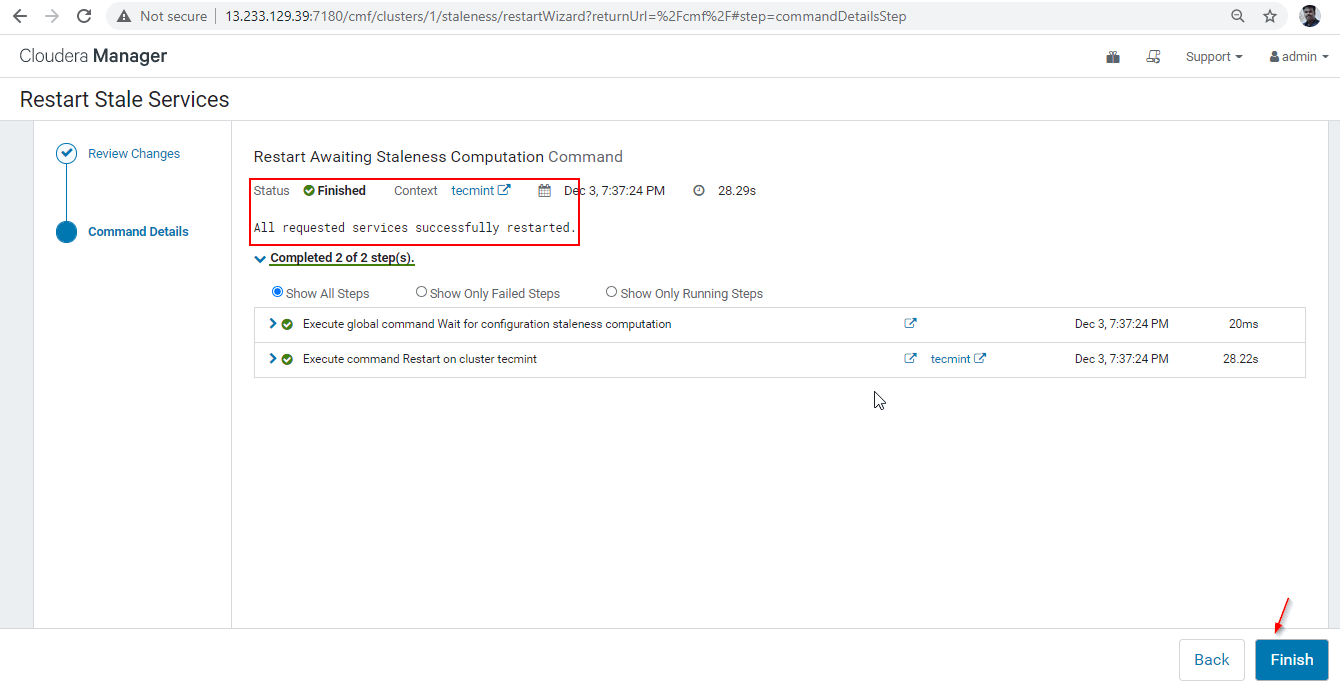
29. 再起動が正常に完了すると、ステータス「完了」が表示されます。 [完了] をクリックしてプロセスを完了します。
30. 次に、Zookeeper Discovery モードを使用して Hiveserver2 に接続します。 JDBC 接続では、ポート番号 2081 の Zookeeper サーバーを使用するために必要な文字列。 Cloudera Manager –> Zookeeper –> インスタンス –> に移動して、Zookeeper サーバーを収集します (サーバー名をメモします)。
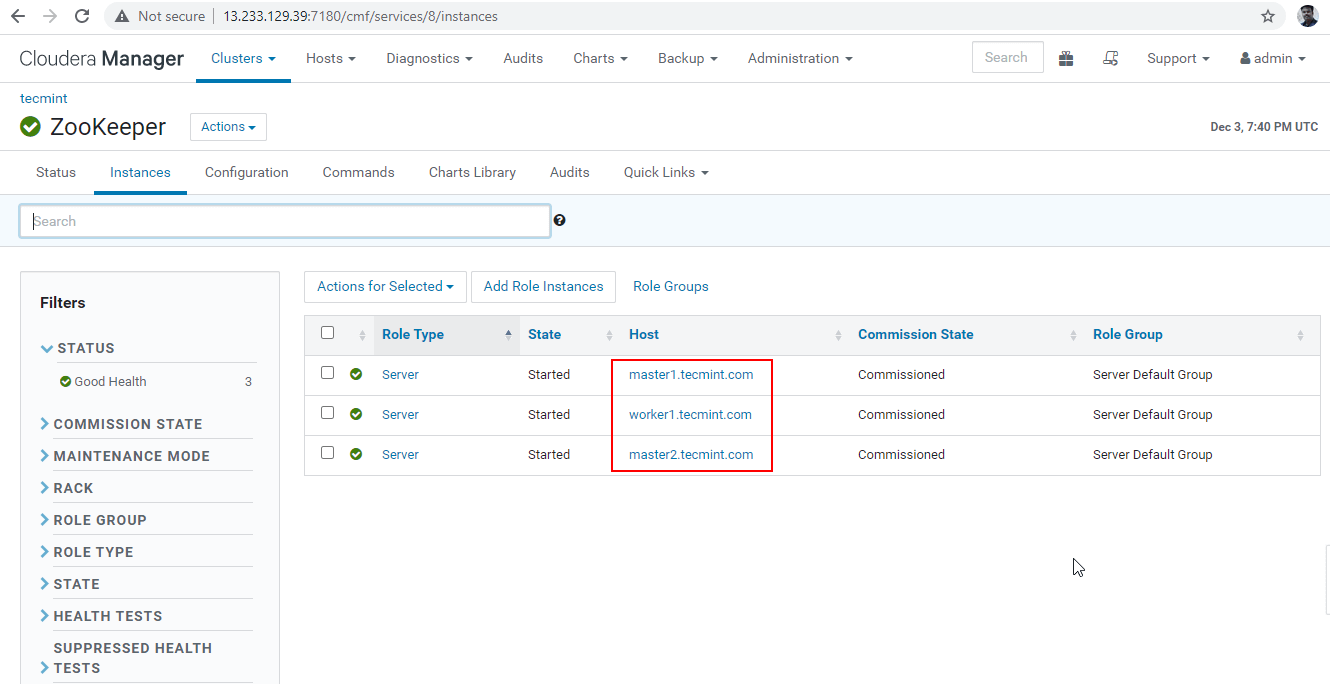
これらは Zookeeper を備えた 3 つのサーバーで、2181 はポート番号です。
master1.linux-console.net:2181
master2.linux-console.net:2181
worker1.linux-console.net:2181
31. それでは直線に入ります。
[tecmint@master1 ~]$ beeline

32. 以下に示すように、JDBC 接続文字列を入力します。 サービス検出モードとZookeeper 名前空間について言及する必要があります。 「hiveserver2」は、Hiveserver2 のデフォルトの名前空間です。
beeline>!connect "jdbc:hive2://master1.linux-console.net:2181,master2.linux-console.net:2181,worker1.linux-console.net:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

33. これで、セッションは master1 で実行されている Hiveserver2 に接続されました。サンプル クエリを実行して検証します。以下のコマンドを使用してデータベースを作成します。
0: jdbc:hive2://master1.linux-console.net:2181,mast> create database tecmint;

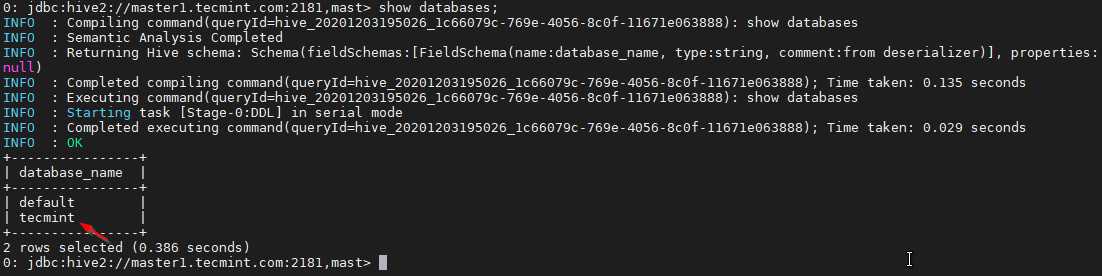
34. 以下のコマンドを使用してデータベースを一覧表示します。
0: jdbc:hive2://master1.linux-console.net:2181,mast> show databases;
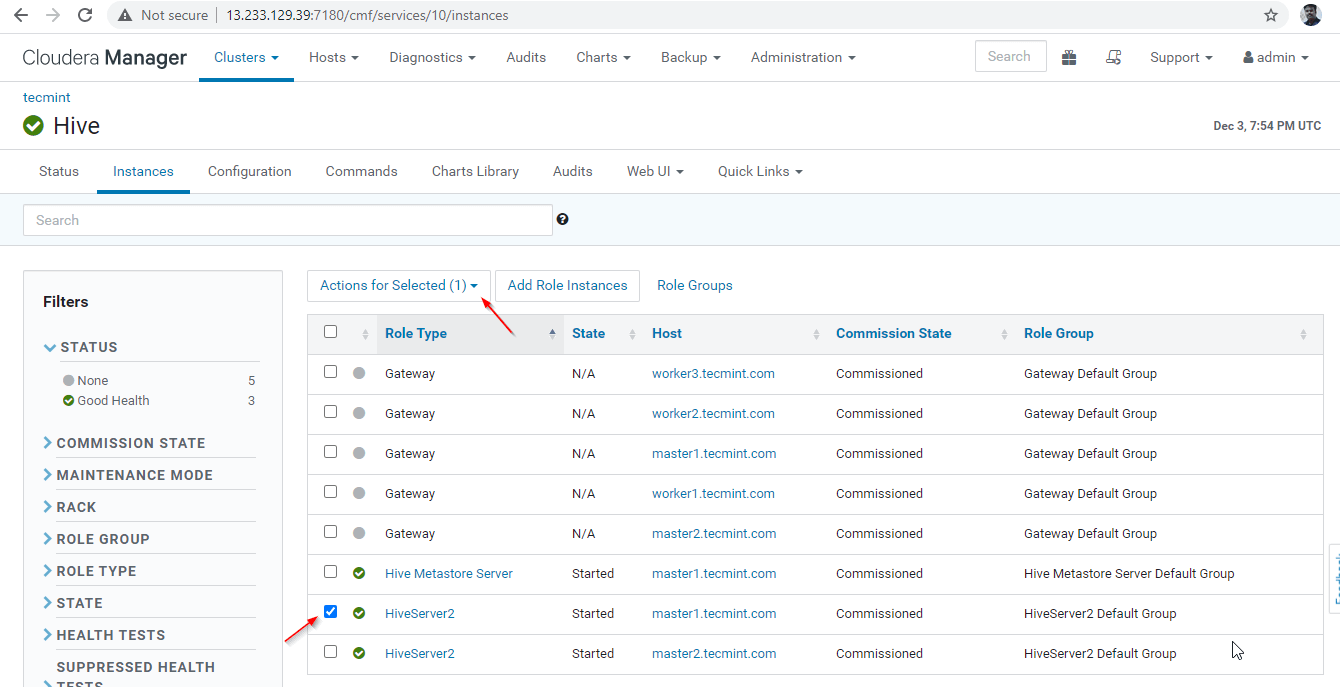
35. 次に、Zookeeper Discovery モードで高可用性を検証します。 Cloudera Manager に移動し、上記でテストした master1 上の Hiveserver2 を停止します。
Cloudera Manager –> Hive –> インスタンス –> (master1 の Hiveserver2 を選択します) ) –> 選択したアクション –> 停止。
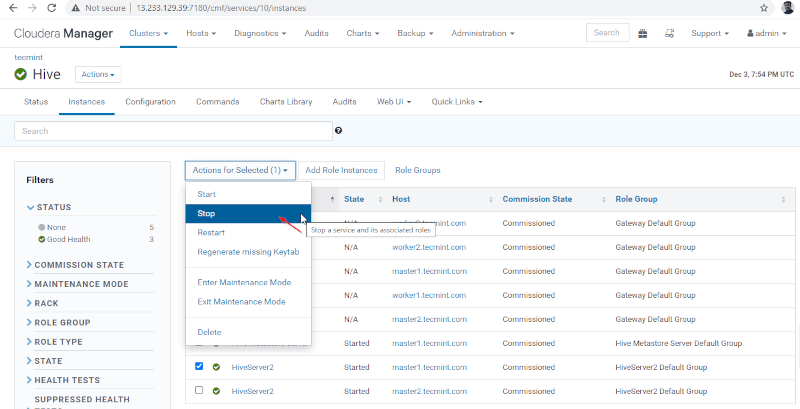
36. [停止] をクリックします。停止すると、ステータスが「完了」になります。 Hive –> Instances に移動して、master1 上の Hiveserver2 を確認します。

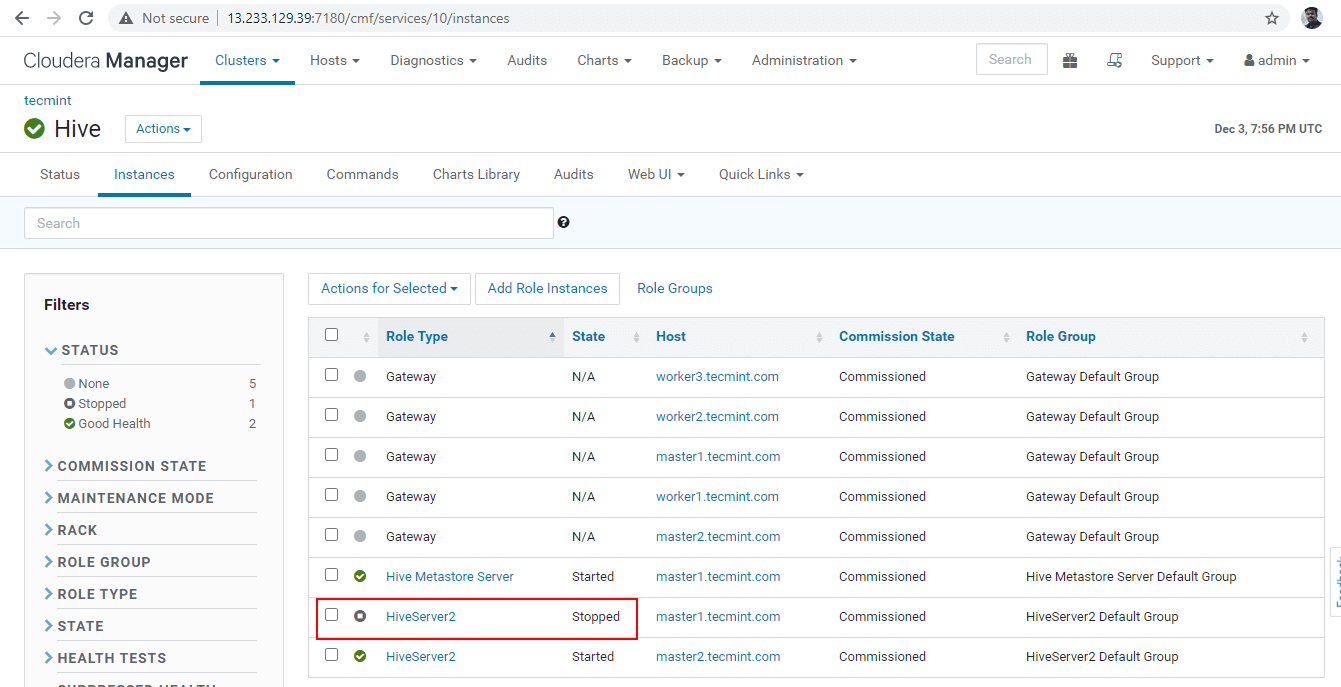
37. ビーラインに入り、Zookeeper Discovery と同じJDBC接続文字列を使用してHiveserver2に接続します。上記の手順で行ったように、 モードにします。
[tecmint@master1 ~]$ beeline
beeline>!connect "jdbc:hive2://master1.linux-console.net:2181,master2.linux-console.net:2181,worker1.linux-console.net:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

これで、マスター 2 で実行されている Hiveserver2 に接続されます。
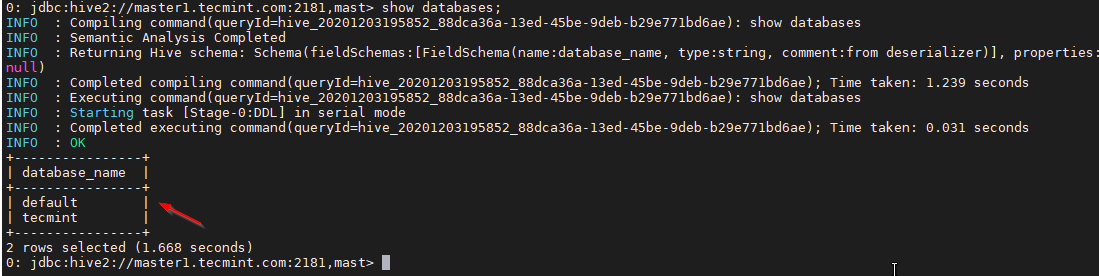
38. サンプル クエリを使用して検証します。
0: jdbc:hive2://master1.linux-console.net:2181,mast> show databases;
結論
この記事では、高可用性を備えたクラスターにHive データ ウェアハウスモデルを導入するための詳細な手順を説明しました。リアルタイム運用環境では、3 つ以上のHiveserver2がZookeeper Discovery モードを有効にして配置されます。
ここでは、 すべてのHiveserver2 が共通の名前空間の下でZookeeperに登録しています。 Zookeeper は動的に利用可能なHiveserver2を検出し、Hive セッションを確立します。